Collection
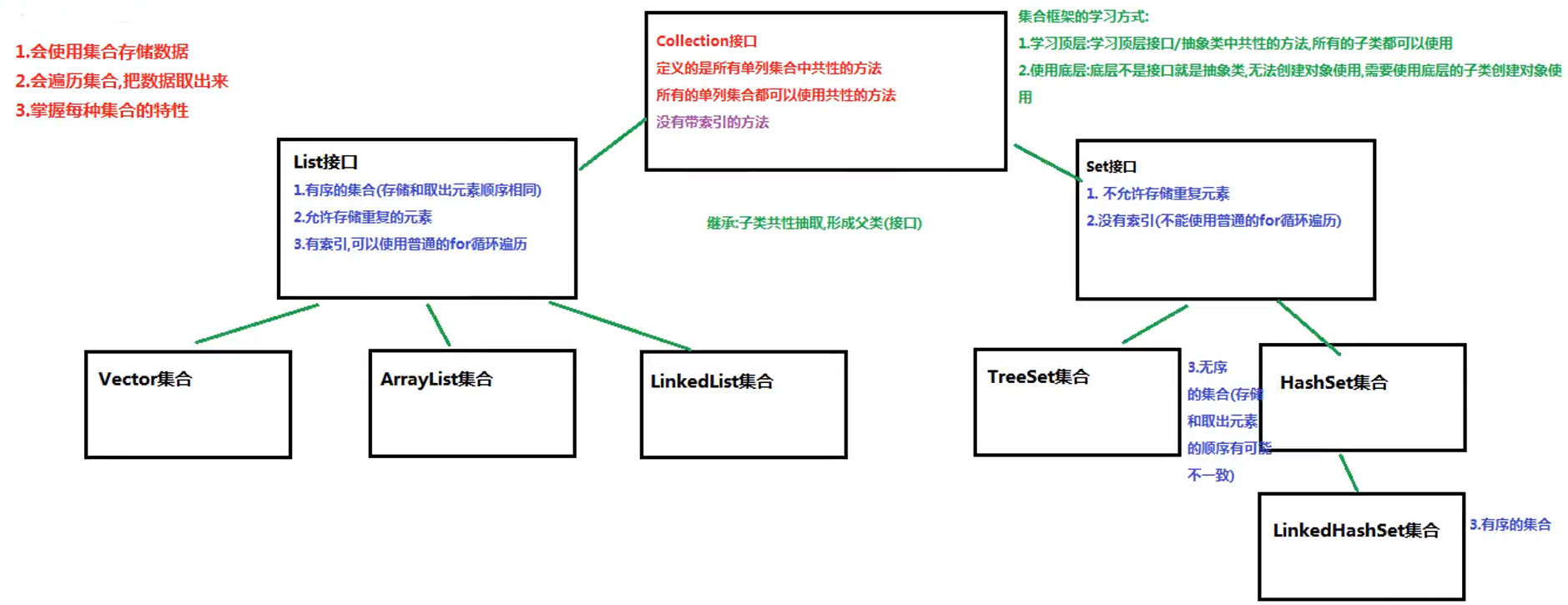
List(有序,可重复)
ArrayList
ArrayList集合(详细转向Array/ArrarList 常用方法)
特点:
1.数字长度可以任意变化
2.
注意:泛型只能是引用类型不能是基本类型
3.对于ArrayList来说直接打印的得到的不是地址值而是内容,如果内容为空则打印[]
ArrayList 底层是数据存储结构是数组,元素增删慢,查询快;
LinkedList
java.util.LinkList 集合 implements List
LinkList 集合 存储的结构是链表结构,查询慢,增删快
包含大量操作首尾元素方法:
public void addFirst(E e):将指定元素插入此列表的开头
public void addLast(E e):将指定元素插入此列表的结尾
public void push(E e):将此元素推入此列表表示的堆栈
public E getFirst():返回列表的第一个元素
public E getLast():返回列表的最后一个元素
public E removeFirst(E e):移除列表的第一个元素,并返回该元素
public E removeLast(E e):移除列表的最后一个元素,并返回该元素
public E pop():从此列表表示的堆栈处返回一个元素
public boolean isEmpty(): 如果此列表为空返回true
1 | LinkedList<String> linkedList=new LinkedList<>(); |
Set(无序,唯一)
java.util.Set extends Collection
Set接口的特点:
1.不允许重复元素
2.没有索引,没有带索引的方法,不能用for循环
HashSet
java.util.HashSet extends Set
特点:
包含set特点
1.是一个无序元素集合,存储元素和取出元素的顺序可能不一致
2.底层是一个哈希结构表(存取速度快)
1 | Set<Integer> hashSet = new HashSet<>(); |
HashCode
哈希值:是一个十进制的整数,由系统随机给出。(就是对象的地址值,是一个逻辑地址,是模拟出来得到地址,不是实际的物理地址)
在Object类有一个方法可以获得对象的哈希值
int hashCode(); 返回对象的哈希值码
HashCode方法的源码:
public native int hashCode();
native 代表该方法调用的是本地操作系统的方法
Object的toString()输出的也是哈希值
1 | bject object=new Object(); |
LinkedHashSet
java.util.linkedHashSet 集合 extend HashSet集合
LinkedHashSet: 底层是一个哈希表(数组+链表/红黑树)+链表:多了一条链表(记录元素的存储顺序),保证元素有序。
1 | HashSet<String> linkedSet=new LinkedHashSet<>(); |
Map(键值对)
Map集合特点
java.util.map<k,v>集合
1.Map集合中元素是一个双列集合,一个元素可以包含两个值(一个key,一个值);
2.Map集合中的元素,key和value的数据类型可以相同,亦可以不同
3.Map集合中的元素,key是不允许重复的,value是允许重复的
4.Map集合中,key和value是一一对应的
HashMap集合的特点:
java.util.HashMap<k,v>集合 implements Map<k,v> 接口
1.HashMap集合的底层是哈希表:查询速度快
jdk1.8之前:数组+单向链表
jdk1.8之前:数组+单向链表/红黑树(链表的长度超过8);提高查询速度
2.HashMap集合是一个无序的集合,存储元素和取出元素的顺序有可能不一致
LinkedHashMap特点:
java.util.linkedHashMap<k,v> extends HashMap<k,v> 集合
1.linkedHashMap底层是哈希表+链表
2.linkedHashMap集合是一个有序集合,存储元素和取出元素是一致的
Map集合常用方法
1 | /* |